What is GPT-4V? How to purchase and use GPT-4V
GPT-4V stands for: the visual version of GPT-4 (GPT-4 Vision), enabling users to guide GPT-4 in analyzing input images. It’s the newest functionality released by OpenAI. In simple terms, GPT-4V is the GPT-4 that can handle images.
How to Purchase and Use GPT-4V Multimodal Technology?
OpenAI’s released GPT-4V multimodal tech is currently accessible to ChatGPT Plus users from October onwards. So, after upgrading to a Plus membership, you can experience the GPT-4V multimodal technology. For upgrade details, refer to our previous article Purchase GPT-4V Multimodal.
How was GPT-4V Trained?
OpenAI released a 19-page technical report today, explaining the latest model, GPT-4V(ision). The paper’s link is: GPT-4V Technical Principles. According to the official introduction from OpenAI, GPT-4V was trained as early as 2022 and provided early access from March 2023. This included collaboration with the Be My Eyes tool for the visually impaired and 1,000 alpha developer users.
The tech behind GPT-4V mainly derives from GPT-4, so the training process is the same. It was pre-trained with a massive amount of text and image data, then fine-tuned using RLHF. To ensure GPT-4V’s safety, OpenAI conducted extensive alignment work during this beta phase, including qualitative and quantitative evaluations, red team tests, and mitigation measures.
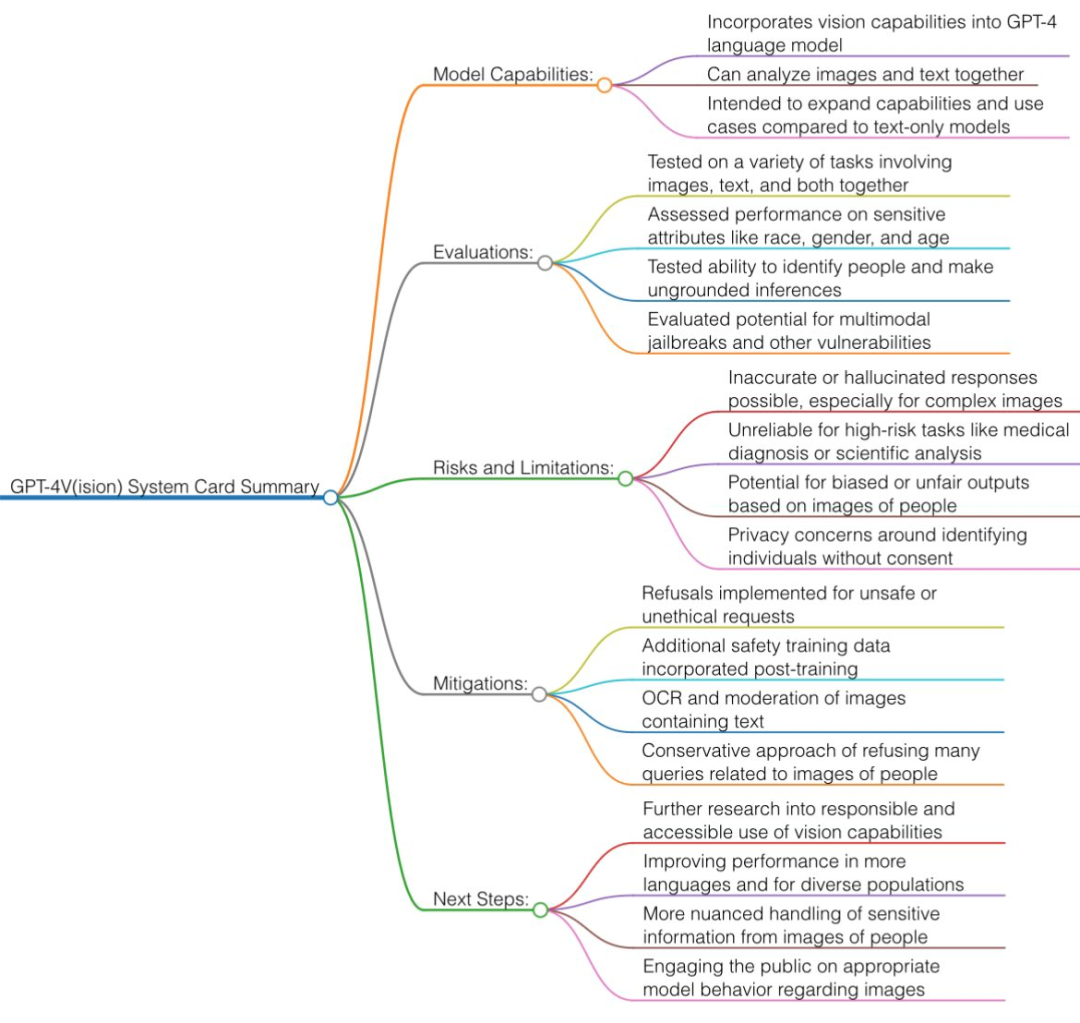
From the OpenAI documentation, we can summarize GPT-4V’s features:
- It’s a (visual, text) to text model, trained with a mix of internet images and text data to predict the next word token, and then with RLHF. Today’s GPT-4V has improved OCR (reading text from pixels) capability.
- Safety restrictions: GPT-4V has a high rejection rate in many categories. For instance, when asked to answer sensitive demographic questions, identify celebrities, recognize geographical locations from backgrounds, or solve captchas, it now says, “Sorry, I can’t help with that.”
- Multimodal attacks: It’s a novel direction. For instance, you can upload a screenshot with malicious prompts (like the infamous “DAN” prompt) or draw mysterious symbols on a napkin to somehow disable filters.
- In serious scientific literature (like medicine), GPT-4V still produces hallucinations, partly because of inaccurate OCR. So, don’t ever take medical advice from any GPT!
Technical Principle of GPT-4V
Based on similar AI research, we can infer that multimodal AI models usually transform text and images into a shared encoding space, allowing them to process different data types via the same neural network. OpenAI might use CLIP to bridge visual data and text data, integrating image and text representations into the same latent space (a vectorized data network). This technology allows ChatGPT to make context inferences across text and images.
What Capabilities Does The Newly Released Multimodal GPT-4V of ChatGPT Have?
Considering all the demo videos and contents in the GPT-4V System Card, internet enthusiasts have quickly summarized the visual capabilities of GPT-4V.
Main Abilities and Application Directions of GPT-4V
- Object Detection: It can identify and detect various common objects in images, such as cars, animals, and household items.
- Text Recognition: Equipped with Optical Character Recognition (OCR), it can find printed or handwritten text in images and convert it to machine-readable text.
- Face Recognition: It can locate and identify faces in images and can somewhat infer gender, age, and racial attributes from facial features.
- Captcha Solutions: Demonstrates visual reasoning abilities in solving text and image-based captchas.
- Geographic Location: Can recognize cities or geographic locations shown in landscape images.
- Complex Images: Struggles with complex scientific charts, medical scans, or images with multiple overlapping text components.
Current Limitations of GPT-4V
However, due to current technological capabilities, there are some limitations:
- Spatial Relationships: Might struggle to understand precise spatial layouts and positions.
- Object Overlap: May confuse the end of one object with the beginning of another in overlapping scenarios.
- Foreground/Background: May not always accurately identify objects.
- Obstructions: Might fail to recognize obstructed objects or overlook associations.
- Details: Can overlook or misunderstand minor objects, texts, or complex details.
- Contextual Reasoning: Lacks robust visual reasoning capabilities.
- Confidence: May wrongly describe object relationships, not aligning with image content.
